
Bigdata Session 2 - Apache Spark
Tweetin data-science · Sun 02 June 2019
in data-science · Sun 02 June 2019
This blog series includes 4 workshop sessions I conducted at Engineering colleges and in my office.
In this workshop, we cover how spark internals works and how we can configure spark with apache yarn resource manager. I’m using docker based setup for this workshop.
Bigdata Session 1 - Apache Hadoop
Bigdata Session 2 - Apache Spark on Apache Hadoop ← ( You are here now )
Bigdata Session 3 - Apache Drill
Bigdata Session 4 - Apache Spark on Kubernetes
Spark is a general-purpose distributed analytic engine.
Spark can execute tasks in DAG with lazy evaluation for better query optimization.
Spark can be deployed in cluster form to execute tasks across multiple machines.
For this workshop, we are covering the Spark over Yarn setup. Which is more scalable and has more cluster management options provided by Yarn resource manager.
Run spark cluster without Hadoop or any of the bellow mentioned cluster managers. Spark shipped with this Standalone default cluster manager. We can easily set up a spark cluster using this.
Here we aren’t covering it, Yarn based cluster manager has more advanced features and resource controllers. We are focusing mainly Yarn based cluster manager here.
This document discusses more how we handle the spark on the Yarn cluster. Please read further to see more about it.
We will cover this on the 4’th session of the Bigdata workshop.
Mesos is another cluster resource manager like Yarn, we aren’t covering more on it here.
|
Note
|
Mac and Windows users have to provide enough memory and CPUs to the docker daemon. On these machines the docker daemon runs under a virtual machine; the installer setup all these. The default size gives is around 2 CPU core and 2gb. Ensure your provision at least 5GB RAM and 3Core CPU for docker daemon to play around with bellow experiments. |
We already covered this part, in our session 1. Let’s add some extra memory constraints when launching the nodes to get more ideas of how yarn manages the resources. Here we are exposing the required ports to the host machines to see the Web interfaces of RN and HDFS.
# Launch namenode with 2 core CPU, 2gb memory.
#
docker run -it -d --name namenode \
-p 8088:8088 \
-p 50070:50070 \
--memory 2g --cpus 2
--network hadoop-nw haridasn/hadoop-2.8.5 namenode
#
# 8088 - RN web interface
# 50070 - HDFS web interface.
#
#
# Datanode 1, 2
docker run -it -d --name datanode1 \
--memory 2g --cpus 2 \
--network hadoop-nw haridasn/hadoop-2.8.5 datanode <namenode-ip>
docker run -it -d --name datanode2 \
--memory 2g --cpus 2 \
--network hadoop-nw haridasn/hadoop-2.8.5 datanode <namenode-ip>Check the container memory allocation status using the docker stats command.
docker run -it -d --name hadoop-cli --network hadoop-nw haridasn/hadoop-cli
# Add the Hadoop configuration to the hadoop-client container.
# You can skip this if you already have done this.
docker cp namenode:/opt/hadoop/etc .
docker cp etc hadoop-cli:/opt/hadoop/docker pull haridasn/spark-2.4.0
docker run -it -d --name spark --network hadoop-nw haridasn/spark-2.4.0# Get the hadoop configurations.
docker cp namenode:/opt/hadoop/etc .
docker cp etc/hadoop spark:/opt/spark/hadoop-confWhen connecting spark with YARN, you need a staging directory to manage the application
details on the HDFS. The variable which manages this is spark.yarn.stagingDir.
Create a directory under hdfs using the hadoop-cli hadoop client and ensure it got
correct directory permissions.
docker exec -it hadoop-cli bash
./bin/hdfs dfs -mkdir /user/spark
./bin/hdfs dfs -chown spark:spark /user/spark
./bin/hdfs dfs -ls /user/spark# Connect to the spark container to play with it.
docker exec -it spark bash
# Inside the spark docker
#
export HADOOP_CONF_DIR=/opt/hadoop-conf
# Try on scala client.
spark-shell --master yarn --deploy-mode client
# Try on python client.
pyspark --master yarn --deploy-mode client
# connect via jupyter notebok, so we can use python to write
# spark jobs via pyspark.
jupyter notebook --no-browser --ip=0.0.0.0 --port 8090|
Note
|
Check out the command-line options pyspark --help to know more options
that we can try when submitting the jobs or running as client mode.
|
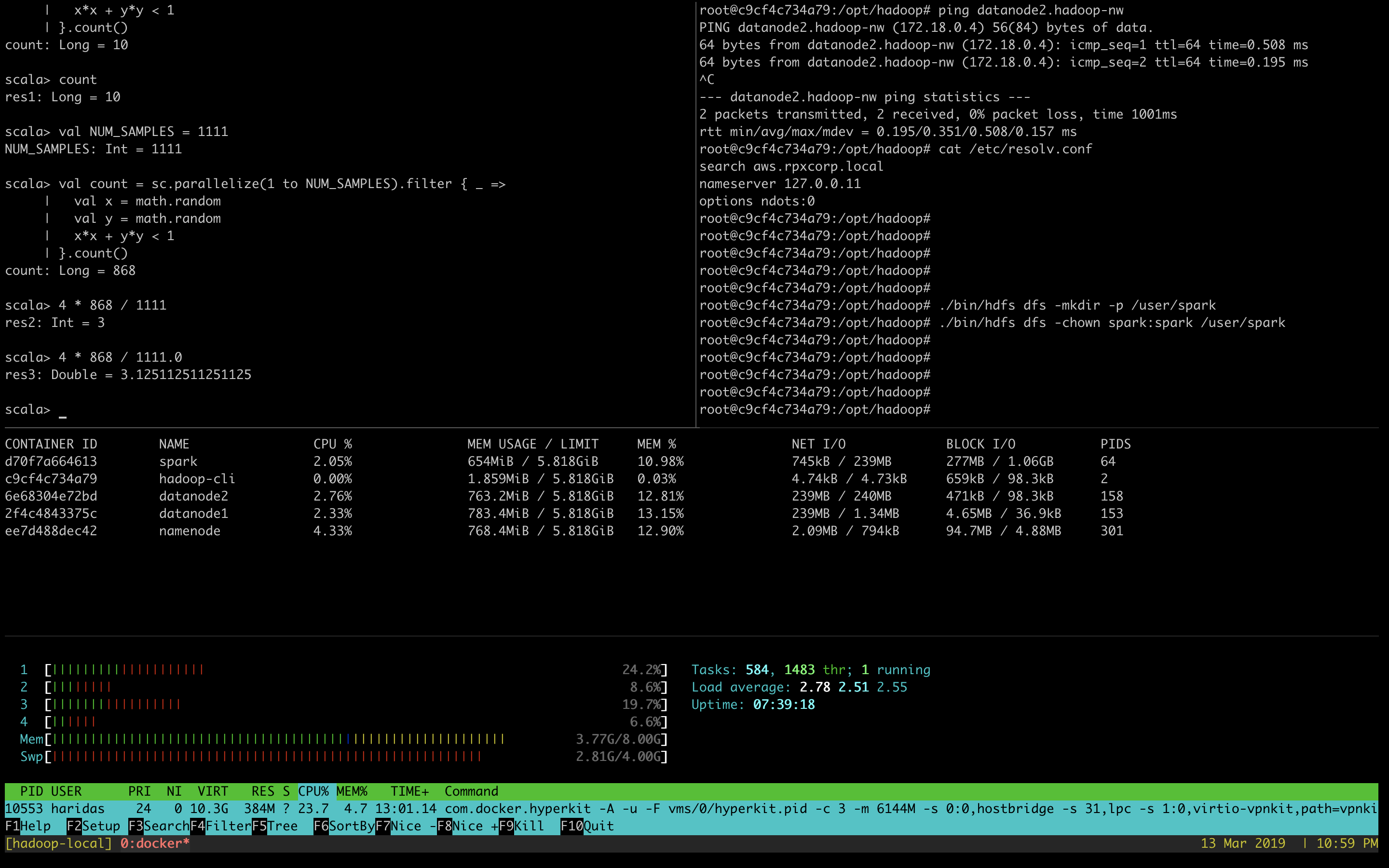
As we are running all the services via docker ensure that the containers are getting enough resources so that we can play with spark using some smaller size data set to under stand how the APIs and other features work in spark.
# To get the ideas about container resource consumption CPU/RAM/IO
# Ensure you have enough left.
docker statsThe test setup is worked well on:-
Test cluster setup on my laptop with 4 core CPU and 8GB memory.
Allocated
5GB for docker daemon running on your laptop.
3 Core for docker daemon on your laptop.My Setup:-
Try more examples from this link: https://spark.apache.org/examples.html